UDX
UDX
-
地理模型程序的开发可以采用各种不同的编程语言,如Fortran,C/C++,Python,Matlab,C#,R等。但从程序设计的基本要素来看,数据结构(Data Structure)和算法(Algorithm)两者组成了地理模型程序的基本内容。无论地理模型对外暴露的数据接口或复杂或简单,在模型程序中都需要映射为相应的数据结构,而变量(Variables)在其中起到最为基础的作用。通过变量之间的组合和关联,能够在程序中实现任意复杂的数据结构。根据W3C XML Schema规范,变量的类型主要有三大类:原子类型(Atomic),表示变量是简单变量,如float,double,decimal,duration,datetime等;数组类型(List),是由某个原子类型的序列数组构成,如List
或者double[10]等;组合类型(Union),是指由几个类型组合而成的,如用int表示年龄、用float表示身高、用string表示姓名、用List 表示几门功课的成绩,这几个类型共同组合而成了一个学生Student类型。 -
类比于这种通过变量组合来支撑模型程序执行逻辑的思路,本研究所设计的统一数据表达-交换模型的UML图如图2.15所示。在统一数据表达-交换模型中,主要有两个基本元素:节点(Node)与核(Kernel)。
-
Node负责组织模型数据的结构,每个Node都拥有自己的名称(Name)和子节点(NodeChildren);在NodeChildren中又包含了相应的节点及其子节点。通过这种层次化的组织,能够灵活的构造出各种数据结构。Kernel负责对具体数据的存储,其中Kernel的数据类型由DTKernel来管理。总体上,Node控制数据的组织结构,Kernel管理数据的具体类型和内容。
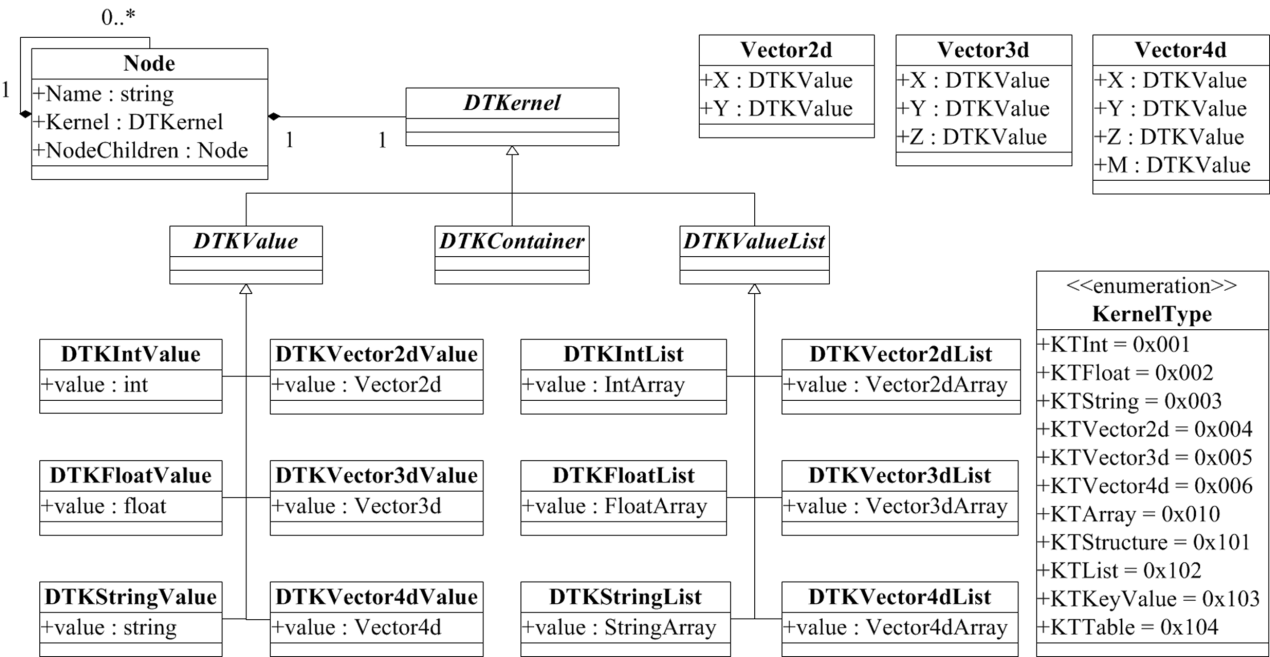
图2.15 统一数据表达-交换模型的对象结构图
-
对于DTKernel而言,主要有三大类:简单数值类型(DTKValue),数组类型(DTKValueList)和复杂容器类型(DTKContainer)。这三大类Kernel可以分别对应到W3C规范所定义的原子类型,数组类型和组合类型。
-
相比于W3C中规定的原子类型,DTKValue中包含的简单数值类型更为具体。事实上,在不同的编程语言平台中,包含了大量的形式各异的变量类型,尤其是在高级的编程语言平台(如.Net的C#语言等);一些常用的、稳定的组合类型往往会被定义成为一个原子类型,以方便用户和编程人员使用,典型的如DateTime,Matrix等。但在模型数据规格描述的过程中,这些变量类型又会对模型使用者的理解造成新的困扰;如DateTime类型,一般而言是指年月日,也可以是月日年,而在水文模型中通常使用“儒略日”来表示日期。如果对每种变量类型都进行描述,将会面临不断引入新的类型条目的困扰。因此,在统一数据表达-交换模型中,DTKValue只包含了DTKIntValue(表示整数类型),DTKFloatValue(表示小数类型),DTKStringValue(表示字符串类型),DTKVector2dValue(表示二维量),DTKVector3dValue(表示三维量),DTKVector4dValue(表示四维量)。其他的类型都可以通过这几种基本类型组合而成。比如一个四维的矩阵Matrix,可以用四个Vector4d来表达,也可以用16个Float表达。默认支持的Float类型就是64位浮点数,若是要表达32位的浮点数,可以在Float型节点关联一个Int型的节点,并指明其为32位。
-
在DTKValueList中,主要用于表达一系列同类型的数据,比如一年的月平均降水量,可以用DTKFloatList来表达。DTKValueList对应于DTKValue,有DTKIntList,DTKFloatList,DTKStringList,DTKVector2dList,DTKVector3dList,DTKVector4dList六种具体类型。
-
一个节点的Kernel属于DTKValue或者DTKValueList类型,则该节点都不可以拥有子节点。而节点的Kernel属于DTKContainer类型时,则该节点可以拥有任意个数的子节点。在DTKContainer中,有四种具体的容器类型:DTKStructure,DTKList,DTKKeyValue,DTKTable。
- (1)DTKStructure是结构体类型,如果一个节点的Kernel属于此类型,则该节点可以拥有多个任意类型的子节点。
- (2)DTKList是集合类型,如果一个节点的Kernel是集合类型,该节点可以拥有多个同构的子节点;同构是指这些子节点的类型可以是DTKValue,DTKValueList,也可以是DTKStructure,但所有节点的类型必须保持一致。DTKList与DTKValueList中几个List的区别就在于DTKList可以是任意类型的集合,而DTKValueList只能是数值的集合。
- (3)DTKKeyValue是键值对类型,如果一个节点的Kernel是键值对类型,该节点需要有一个单独的节点作为主键(key)节点,与主键节点并列的一个值(value)节点,值节点可以是任意类型来对应不同的信息。
- (4)DTKTable是表结构类型,如果一个节点的Kernel是表结构类型,该节点可以拥有任意多个DTKValueList类型的子节点。每个DTKValueList子节点都是表结构中的一列,列名则直接以子节点的名称表达。

- 在表2.1中,用XML序列化的方式对统一数据表达-交换模型中的节点Kernel类型进行了示例的描述(其中Node按照XDO元素来标记和组织)。在示例中,地形分析模型中涉及到“汇流累积量阈值”用Float型节点表达(a.2),“流域边界”用Vector2dList型节点表达(b.4),“子流域属性”用Structure型节点表达,在其子节点中用String节点表达“子流域名称”,用Float节点表达“子流域面积”,用Vector2dList节点表达“子流域边界”。
UDX & UDX Schema
一个是统一数据表达UDX Schema,还有一个是统一数据交换UDX Data,两者共同构成了统一数据表达-交换模型的内容。
- UDX Schema和UDX Data两者在结构层次是同构的,都是基于统一的Node-Kernel结构。而UDX Schema负责对模型数据内容进行详尽的描述,UDX Data则是严格匹配于UDX Schema的具体数据内容。
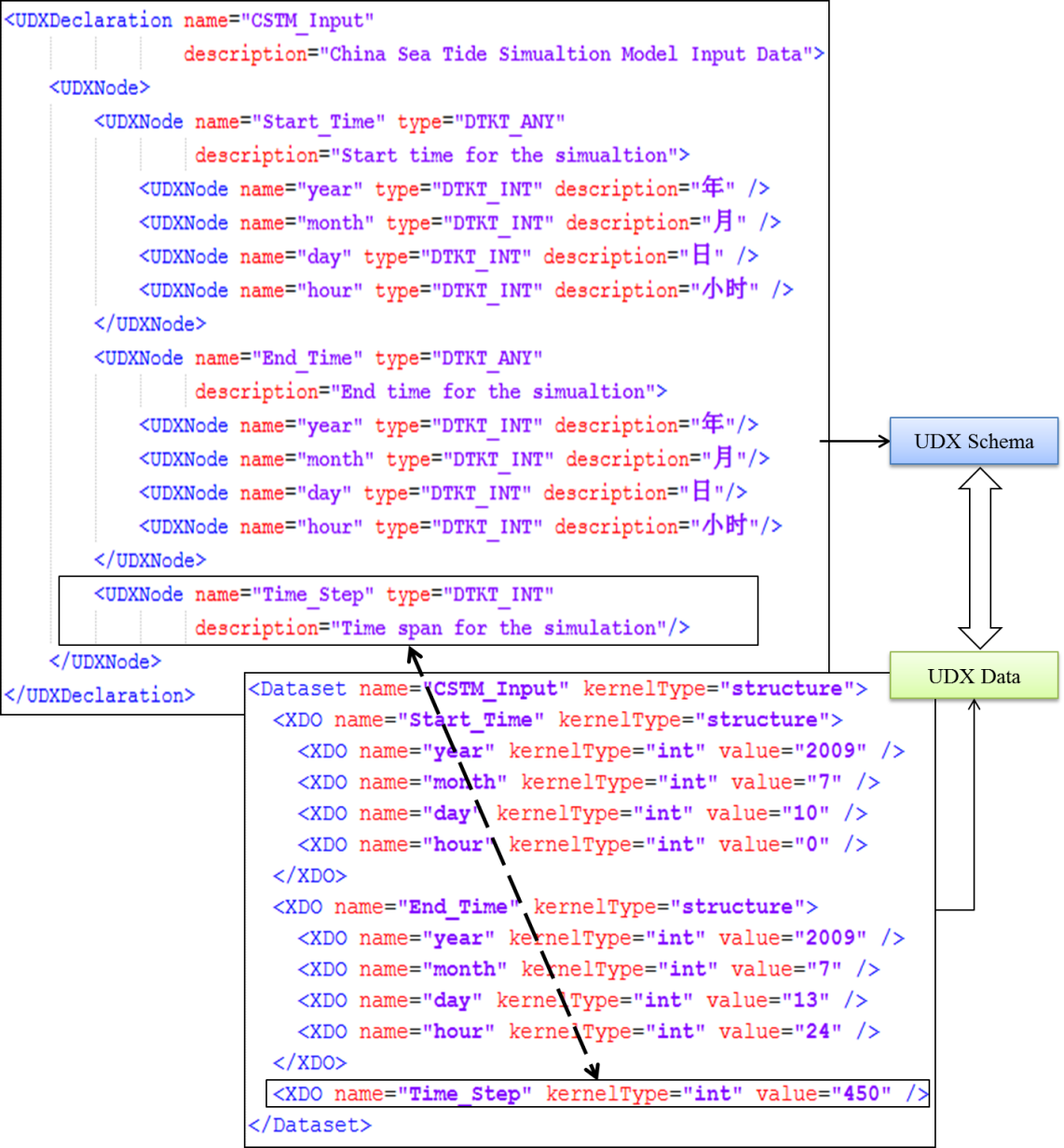
对于地理模型数据,UDX Data是具体数据内容的存储,UDX Schema则对地理模型数据规格在形式和结构层面的描述。
eg SWAT
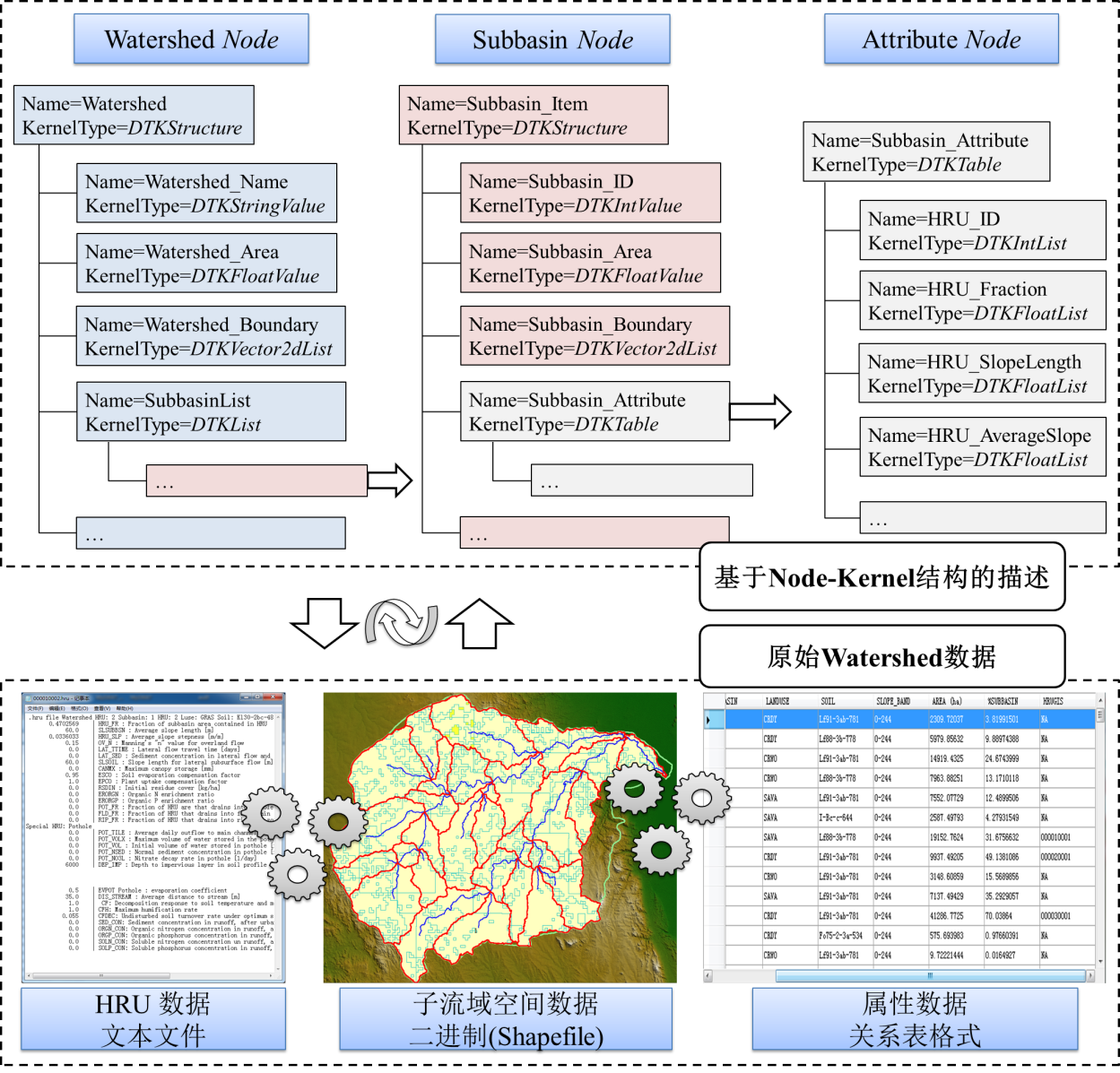
- 在图2.18中利用UDX Schema对SWAT模型中水文响应单元(HRU)等相关数据进行表达。在“流域”节点中包含了名称Watershed_Name节点,流域面积Watershed_Area节点等,其中还有“子流域集合”SubbasinList节点来表达各个子流域的信息。在“子流域”节点中,有Int型的子流域标识Subbasin_ID节点,Float型的子流域面积Subbasin_Area节点,Vector2dList型的子流域边界Subbasin_Boundary节点,此外子流域的属性信息通过Structure型的Subbasin_Attribute节点来表达。在Subbasin_Attribure节点中,包含了一系列的水文相应单元信息,每个水文响应单元都有其标识信息(HRU_ID节点),分维数信息(HRU_Fraction节点),坡长信息(HRU_SlopLength节点),平均坡度信息(HRU_AverageSlope节点)等。这些数据节点都对应到SWAT模型所需的HRU数据的内容结构上。
注意
- Node-Kernel结构的UDX Schema只是在形式和结构层面描述了地理模型的数据规格,数据内容的内蕴信息并没有描述
所以
地理模型数据规格的语义内涵描述
在统一数据表达-交换模型中,设计了辅助资源库来支撑用户表达数据的语义属性相关信息。
- 结合WPS、OpenMI和SEDRIS中对模型数据规格的描述方法,辅助资源库中主要包含以下四大类资源:(1)语义概念资源库:描述模型数据关联的语义概念信息;(2)空间参考资源库:描述模型数据的空间坐标系信息;(3)单位量纲资源库:描述模型数据的度量信息;(4)通用数据表达模板库:描述模型数据对应于某一种常用数据格式信息。
总结
-
(1)对于地理模型的表现形式和内容结构,所设计的统一数据表达-交换模型基于构造式的Node-Kernel结构,其具体实现包括UDX Data和UDX Schema,通过在结构上保持严格一致的UDX Data和UDX Schema可以实现对模型数据的表型形式和内容结构统一表达;
-
(2)对于地理模型的内蕴信息,利用统一数据表达-交换模型相关联的语义概念库、空间参考库、单位量纲库和通用数据表达模板库,可以实现对数据内容中各个层次的语义属性信息进行可扩展的表达;
-
(3)同时,利用所设计的扩展谓词函数库,通过构建数据约束文档的方式可以实现地理模型数据规格中与模型运行紧密关联的数据约束条件信息的表达。